Training Data
Training Data
Data Sets the Boundary
If there's no Vietnamese in the training data, the model won't be able to translate from English into Vietnamese. Similarly, if an image classification model sees only animals in its training set, it won't perform well on photos of plants.
More Task Data Can Help
Collection Is Expensive
Available Data Shapes Models
Common Crawl and C4
For example, a common source for training data is Common Crawl, created by a nonprofit organization that sporadically crawls websites on the internet. In 2022 and 2023, this organization crawled approximately 2-3 billion web pages each month. Google provides a clean subset of Common Crawl called the Colossal Clean Crawled Corpus, or C4 for short.
A study by the Washington Post shows that the 1,000 most common websites in the dataset include several media outlets that rank low on NewsGuard's scale for trustworthiness. In lay terms, Common Crawl contains plenty of fake news.
Some teams use heuristics to filter out low-quality data from the internet. For example, OpenAI used only the Reddit links that received at least three upvotes to train GPT-2. While this does help screen out links that nobody cares about, Reddit isn't exactly the pinnacle of propriety and good taste.
Curating for the Work You Need
The "use what we have, not what we want" approach may lead to models that perform well on tasks present in the training data but not necessarily on the tasks you care about.
This section focuses on curating data for specific languages and domains, providing a broad yet specialized foundation for applications within those areas. Chapter 8 explores data strategies for models tailored to highly specific tasks.
While language- and domain-specific foundation models can be trained from scratch, it's also common to finetune them on top of general-purpose models.
The impact of data quality is discussed more in Chapter 8.
Multilingual Models
English dominates the internet. An analysis of the Common Crawl dataset shows that English accounts for almost half of the data (45.88%), making it eight times more prevalent than the second-most common language, Russian (5.97%) (Lai et al., 2023). See Table 2-1 for a list of languages with at least 1% in Common Crawl. Languages with limited availability as training data -- typically languages not included in this list -- are considered low-resource.
Table 2-1. The most common languages in Common Crawl, a popular dataset for training LLMs. Source: Lai et al. (2023).
| Language | Code | Pop. | CC size | |
|---|---|---|---|---|
| (M) | (%) | Cat. | ||
| English | en | 1,452 | 45.8786 | H |
| Russian | ru | 258 | 5.9692 | H |
| German | de | 134 | 5.8811 | H |
| Chinese | zh | 1,118 | 4.8747 | H |
| Japanese | jp | 125 | 4.7884 | H |
| French | fr | 274 | 4.7254 | H |
| Spanish | es | 548 | 4.4690 | H |
| Italian | it | 68 | 2.5712 | H |
| Dutch | nl | 30 | 2.0585 | H |
| Polish | pl | 45 | 1.6636 | H |
| Portuguese | pt | 257 | 1.1505 | H |
| Vietnamese | vi | 85 | 1.0299 | H |
Many other languages, despite having a lot of speakers today, are severely underrepresented in Common Crawl. Table 2-2 shows some of these languages. Ideally, the ratio between world population representation and Common Crawl representation should be 1. The higher this ratio, the more under-represented this language is in Common Crawl.
Table 2-2. Examples of under-represented languages in Common Crawl. The last row, English, is for comparison. The numbers for % in Common Crawl are taken from Lai et al. (2023).
| Language | Speakers (million) | % world population1 | % in Common Crawl | World: Common Crawl Ratio |
|---|---|---|---|---|
| Punjabi | 113 | 1.41% | 0.0061% | 231.56 |
| Swahili | 71 | 0.89% | 0.0077% | 115.26 |
| Urdu | 231 | 2.89% | 0.0274% | 105.38 |
| Kannada | 64 | 0.80% | 0.0122% | 65.57 |
| Telugu | 95 | 1.19% | 0.0183% | 64.89 |
| Gujarati | 62 | 0.78% | 0.0126% | 61.51 |
| Marathi | 99 | 1.24% | 0.0213% | 58.10 |
| Bengali | 272 | 3.40% | 0.0930% | 36.56 |
| English | 1452 | 18.15% | 45.88% | 0.40 |
What Underrepresentation Does
Given the dominance of English in the internet data, it's not surprising that general-purpose models work much better for English than other languages, according to multiple studies.
MMLU
Project Euler
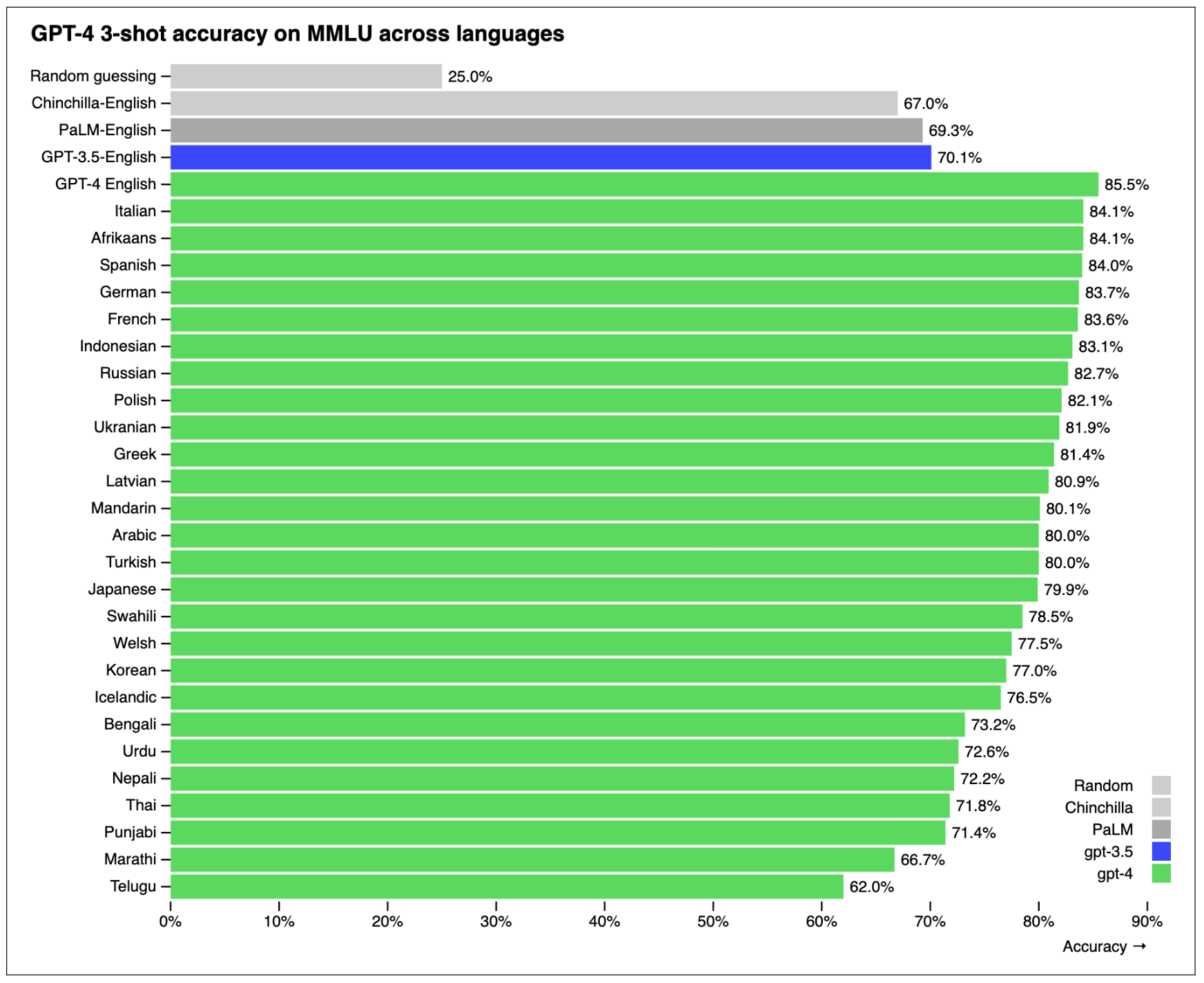
Figure 2-1. On the MMLU benchmark, GPT-4 performs better in English than in any other language. To obtain MMLU in other languages, OpenAI translated the questions using Azure AI Translator.
GPT-4 failed in all six questions for Burmese and Amharic, as shown in Figure 2-2.
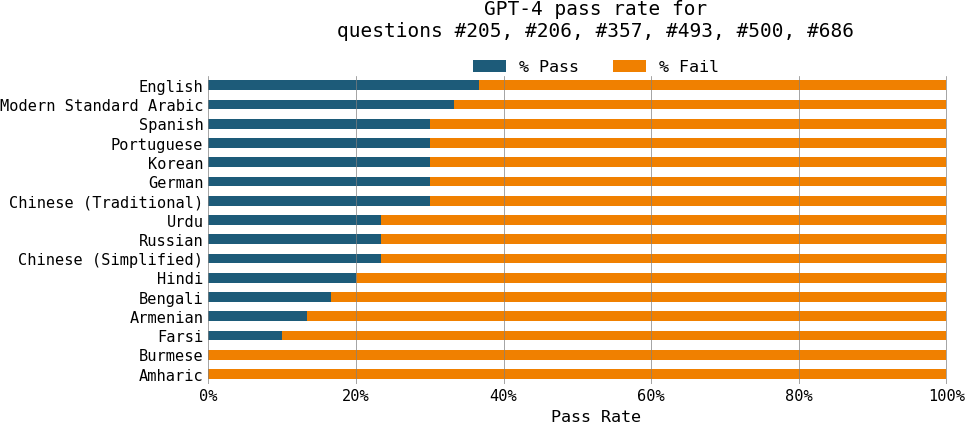
Figure 2-2. GPT-4 is much better at math in English than in other languages.
However, under-representation isn't the only reason. A language's structure and the culture it embodies can also make a language harder for a model to learn.
Why Translation Is Not Enough
Given that LLMs are generally good at translation, can we just translate all queries from other languages into English, obtain the responses, and translate them back into the original language? Many people indeed follow this approach, but it's not ideal.
Translation Requires Understanding
Translation Can Lose Information
Models can also have unexpected performance challenges in non-English languages. For example, NewsGuard found that ChatGPT is more willing to produce misinformation in Chinese than in English.
Tokenization, Latency, and Cost
Other than quality issues, models can also be slower and more expensive for non-English languages. A model's inference latency and cost is proportional to the number of tokens in the input and response. It turns out that tokenization can be much more efficient for some languages than others.
Benchmarking GPT-4 on MASSIVE, a dataset of one million short texts translated across 52 languages, Yennie Jun found that, to convey the same meaning, languages like Burmese and Hindi require a lot more tokens than English or Spanish.
English
Hindi
Burmese
Assuming that the time it takes to generate a token is the same in all languages, GPT-4 takes approximately ten times longer in Burmese than in English for the same content. For APIs that charge by token usage, Burmese costs ten times more than English.
Language-Specific Models
To address this, many models have been trained to focus on non-English languages. The most active language, other than English, is undoubtedly Chinese, with ChatGLM, YAYI, Llama-Chinese, and others.
There are also models in French (CroissantLLM), Vietnamese (PhoGPT), Arabic (Jais), and many more languages.
Domain-Specific Models
General-purpose models like Gemini, GPTs, and Llamas can perform incredibly well on a wide range of domains, including but not limited to coding, law, science, business, sports, and environmental science. This is largely thanks to the inclusion of these domains in their training data.
Figure 2-3 shows the distribution of domains present in Common Crawl according to the Washington Post's 2023 analysis.4
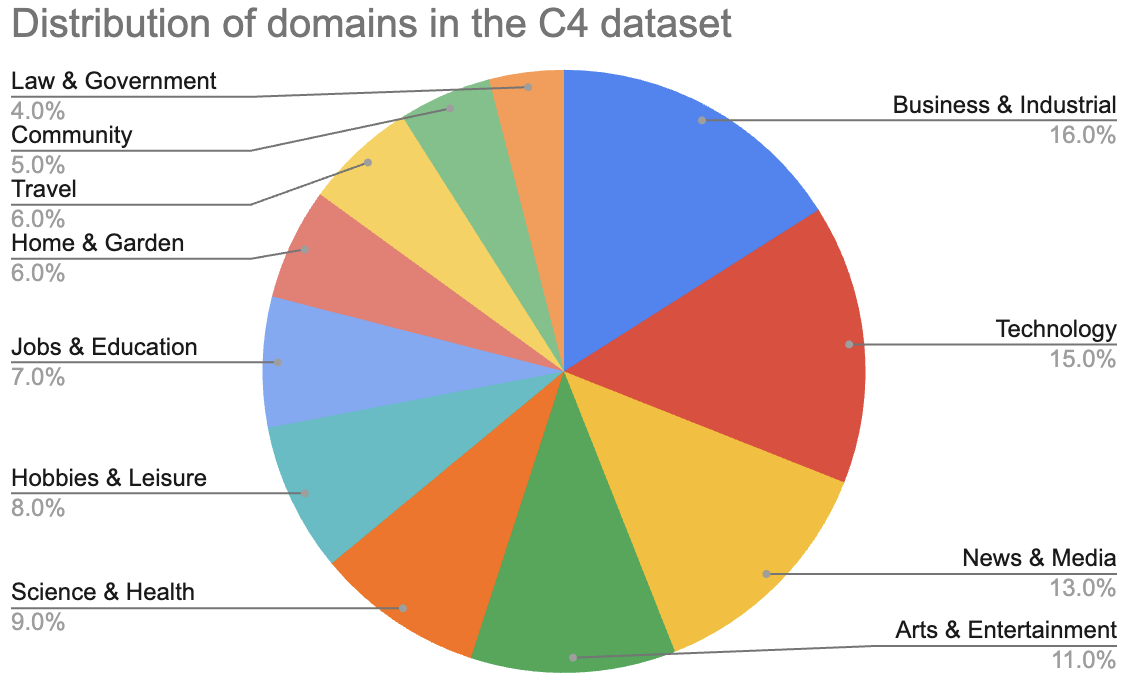
Figure 2-3. Distribution of domains in the C4 dataset. Reproduced from the statistics from the Washington Post. One caveat of this analysis is that it only shows the categories that are included, not the categories missing.
As of this writing, there haven't been many analyses of domain distribution in vision data. This might be because images are harder to categorize than texts.5 However, you can infer a model's domains from its benchmark performance.
Table 2-3 shows how two models, CLIP and Open CLIP, perform on different benchmarks. These benchmarks show how well these two models do on birds, flowers, cars, and a few more categories, but the world is so much bigger and more complex than these few categories.
Table 2-3. Open CLIP and CLIP's performance on different image datasets.
| Dataset | CLIP Accuracy of ViT-B/32 (OpenAI) | Open CLIP Accuracy of ViT-B/32 (Cade) |
|---|---|---|
| ImageNet | 63.2 | 62.9 |
| ImageNet v2 | - | 62.6 |
| Birdsnap | 37.8 | 46.0 |
| Country211 | 17.8 | 14.8 |
| Oxford 102 Category Flower | 66.7 | 66.0 |
| German Traffic Sign Recognition Benchmark | 32.2 | 42.0 |
| Stanford Cars | 59.4 | 79.3 |
| UCF101 | 64.5 | 63.1 |
When General-Purpose Data Is Not Enough
Even though general-purpose foundation models can answer everyday questions about different domains, they are unlikely to perform well on domain-specific tasks, especially if they never saw these tasks during training.
Drug Discovery
Cancer Screening
To train a model to perform well on these domain-specific tasks, you might need to curate very specific datasets.
AlphaFold
BioNeMo
Med-PaLM2
This section gave a high-level overview of how training data impacts a model's performance. Next, let's explore the impact of how a model is designed on its performance.
Footnotes
- A world population of eight billion was used for this calculation. ↩
- "GPT-4 Can Solve Math Problems--but Not in All Languages" by Yennie Jun. You can verify the study using OpenAI's Tokenizer. ↩
- It might be because of some biases in pre-training data or alignment data. Perhaps OpenAI just didn't include as much data in the Chinese language or China-centric narratives to train their models. ↩
- "Inside the Secret List of Websites That Make AI like ChatGPT Sound Smart", Washington Post, 2023. ↩
- For texts, you can use domain keywords as heuristics, but there are no obvious heuristics for images. Most analyses I could find about vision datasets are about image sizes, resolutions, or video lengths. ↩